Correlating Chrome’s 3rd Party Product Names to HTTP Archive Data
One of the exciting new features in Chrome Dev Tools is the addition of 3rd party product names integrated into Dev Tools. I was interested in exploring how this works, and whether any of this data can be used to do further research via the HTTP Archive.
Looking at the Chromium source for productRegistryData, this appears to be implemented with a JSON array containing a database of over 5289 hashes that associate a product ID with another JSON array containing product names.
In order to look up the product names, the browser takes a SHA1 hash of the domain name, and then compares the first 16 characters of the hex string to the hash in productRegistryData. That makes for an efficient lookup in DevTools - but it certainly makes it difficult to compare with a table such as [httparchive:runs.latest-requests].
In my first attempt, I tried converting the JSON array of product details to a CSV file and imported it to a Big Query table I named product_registry. BigQuery has a SHA1() function, so I figured I’d give that a try. Unfortunately it seems that the SHA1() function in returns a hash in bytes, and there is no way to CAST it as a hex string.
It looks like someone else ran into this issue though, and created a user-defined function to convert bytes to a hex string. You can see the details here.
I decided to give this a try, and created the following query. Note: it needs to be run as Standard SQL.
CREATE TEMPORARY FUNCTION
BASE64_TO_HEX_SUBSTRING(code BYTES)
RETURNS STRING
LANGUAGE js AS """
var alphabet = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
var equals = 0;
if (!code || code.length == 0) {
return null;
}
while (code[code.length - 1] == "=") {
equals++;
code = code.slice(0, -1);
}
var binaryRep = "";
var hexRep = "";
var width = 6;
for (var i = 0; i < code.length; i++) {
var index = alphabet.indexOf(code.charAt(i));
var n = (index >>> 0).toString(2);
var bin = n.length >= width ? n : new Array(width - n.length + 1).join('0') + n;
binaryRep += bin;
}
for (var i = 0; i < equals; i++) {
binaryRep = binaryRep.slice(0, -2);
}
for (var i = 0; i < binaryRep.length / 4; i++) {
hexRep += parseInt(binaryRep.charAt(4 * i) + binaryRep.charAt(4 * i + 1) + binaryRep.charAt(4 * i + 2) + binaryRep.charAt(4 * i + 3), 2).toString(16);
}
return hexRep.substr(0,16);
"""
;
SELECT productName, count(*) as `requests`, count(distinct r.pageid) as `pages`,
APPROX_QUANTILES(time/1000, 100)[SAFE_ORDINAL(50)] AS `ResponseTime50th`,
APPROX_QUANTILES(respSize, 100)[SAFE_ORDINAL(50)] AS `ResponseSize50th`,
APPROX_QUANTILES(reqCookieLen, 100)[SAFE_ORDINAL(50)] AS `CookieLength50th`
FROM `thirdparties.products` AS `p`
JOIN (
SELECT req_host, pageid, time, reqCookieLen, respSize
FROM `httparchive.runs.2017_07_01_requests`
) AS `r`
ON p.sha1_substring = BASE64_TO_HEX_SUBSTRING(SHA1(r.req_host))
GROUP by productName
ORDER BY pages DESC
This provides a summary of all 3rd party content identified by the Chromium productRegistryData. Specifically I’m looking at the median response times, response size, and length of cookies sent with the http requests for these resources -
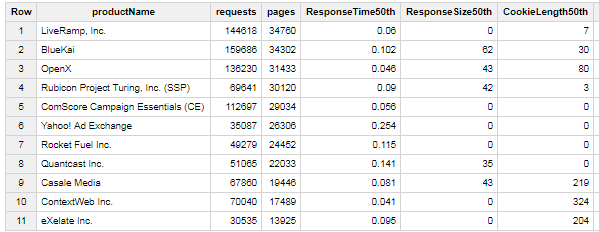
Browsing through the list of 3rd parties, I’ve noticed that there are some gaps, so I’m hoping that this will be useful for both the community looking to understand 3rd party performance - as well as to Chromium for providing a way to correlate their data back to HTTP Archive and improve it’s accuracy over time.
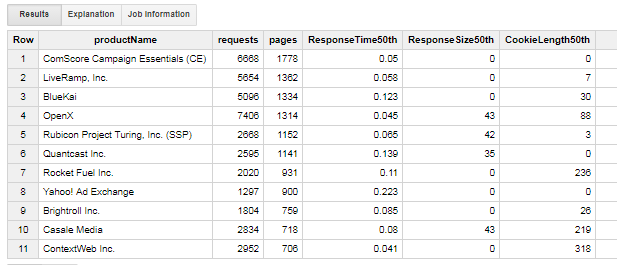
Also, JOINing the pages table to all of this gives us the ability to look at 3rd parties based on Alexa popularity of the sites including them. For example, adding this to the query looks at the Alexa top 10,000 sites:
JOIN (
SELECT pageid, rank
FROM `httparchive.runs.2017_07_01_pages`
) AS `pages`
ON pages.pageid = r.pageid
WHERE rank > 0 and rank < 10000
Originally published at https://discuss.httparchive.org/t/correlating-chromes-3rd-party-product-names-to-http-archive-data/1039
